AI or Not Catches 100% of Deepfake X-Rays. Radiologists Caught 75%.
We ran a 154-image dataset of real and synthetic radiographs through AI or Not, we detected 100% of AI generated x-rays with 95% overall accuracy.

A radiologist looks at roughly a hundred X-rays a day. Now consider: what if 1 in 4 of those images were AI-generated, and the radiologist had no way to tell?
That's not a hypothetical. Researchers at the Icahn School of Medicine at Mount Sinai published a study in Radiology in March 2026 testing exactly this scenario. Seventeen radiologists from six countries were shown a mix of authentic radiographs and images synthesized by GPT-4o. When told to look for fakes, they got it right 75% of the time.
We ran the same curated dataset through AI or Not. We caught 100% of the synthetic images and scored 95% overall.
The study's dataset is public, at https://noneedanick.github.io/DeepFakeXRay/. So we tested against it directly: 154 radiographs, 77 AI-generated and 77 authentic, the exact split the Mount Sinai team used. The gap between what specialists can see and what purpose-built detection can find is wider than most clinicians expect.
Key Takeaways
- AI or Not scored 95% overall accuracy on the Mount Sinai deepfake radiograph dataset (148 of 154 correct), catching every single AI-generated image.
- Radiologists informed that some images might be AI-generated scored 75% on the same dataset type, according to Tordjman and colleagues.
- Four general-purpose LLMs tested in the study ranged from 56% to 85% accuracy, a spread that points to inconsistency rather than any specialized capability.
- Only 7 of 17 radiologists spontaneously raised the possibility that any image was AI-generated before being told to look for fakes.
- The Mount Sinai team found no correlation between years of clinical experience and a radiologist's ability to detect synthetic images.
Why AI or Not: The Head-to-Head Numbers
Here's how the detectors stacked up on the Mount Sinai dataset:
| Detector | Overall accuracy on the Mount Sinai dataset |
|---|---|
| AI or Not | 95% |
| GPT-4o (LLM) | 85% |
| GPT-5 (LLM) | 83% |
| Radiologists (informed) | 75% |
| Radiologists (informed, RoentGen dataset) | 70% |
| Llama 4 Maverick (LLM) | 59% |
| Gemini 2.5 Pro (LLM) | 56% |
| Radiologists (uninformed) | 41% |
Why Radiologists Scored Poorly
Radiologists are trained to find disease, not deception. When they read an X-ray, they're looking for fractures, masses, fluid, and alignment. A generative model can reproduce all of those signals convincingly. But the traces it leaves behind have nothing to do with anatomy: pixel-level inconsistencies and frequency artifacts that no clinical training prepares you to see.
Clinicians aren't trained to look for those markers. They're also working without the color gradients and textural cues that help in standard photograph analysis. Grayscale radiographs offer fewer visual anchors than a face or a landscape. That's part of why X-ray deepfakes trip up human reviewers more often than synthetic photos do.
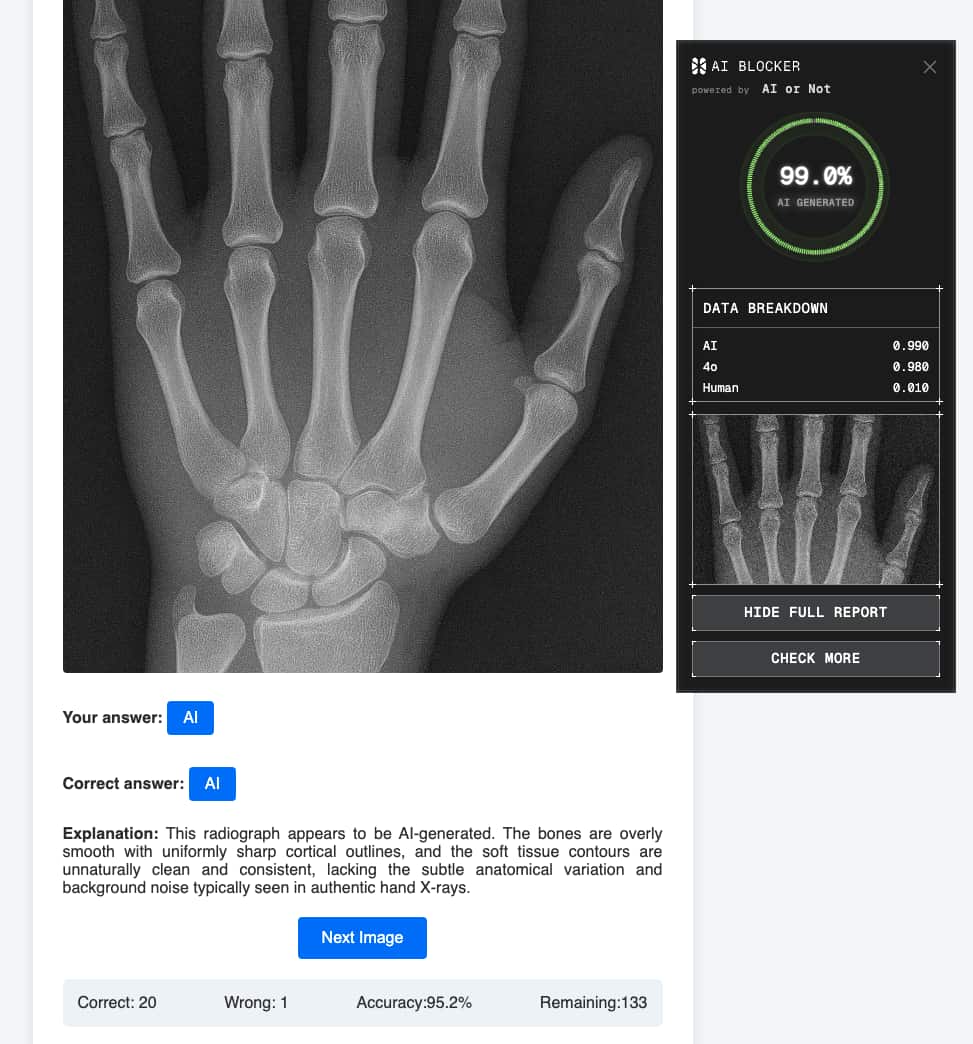
Tordjman and colleagues found no correlation between years of clinical experience and detection accuracy. A radiologist with thirty years of practice performed no better at spotting fakes than one fresh out of residency. And that's the catch. Clinical expertise builds on reading anatomy. It doesn't carry over to deepfake detection, and no amount of experience closes that gap.
Why General-Purpose LLMs Aren't Reliable
The LLM results in the Mount Sinai study carry a specific lesson. GPT-4o scored 85%. Gemini 2.5 Pro scored 56%. That 29-percentage-point spread across four models isn't a sign that some LLMs are trained well for this task. It's evidence that none of them are.
When you ask GPT-5 or Gemini to assess whether a radiograph is synthetic, they're drawing on broad image-recognition training, and none of that training targets the artifacts AI generators embed in synthetic images. They're reasoning about anatomy. Not forensics.
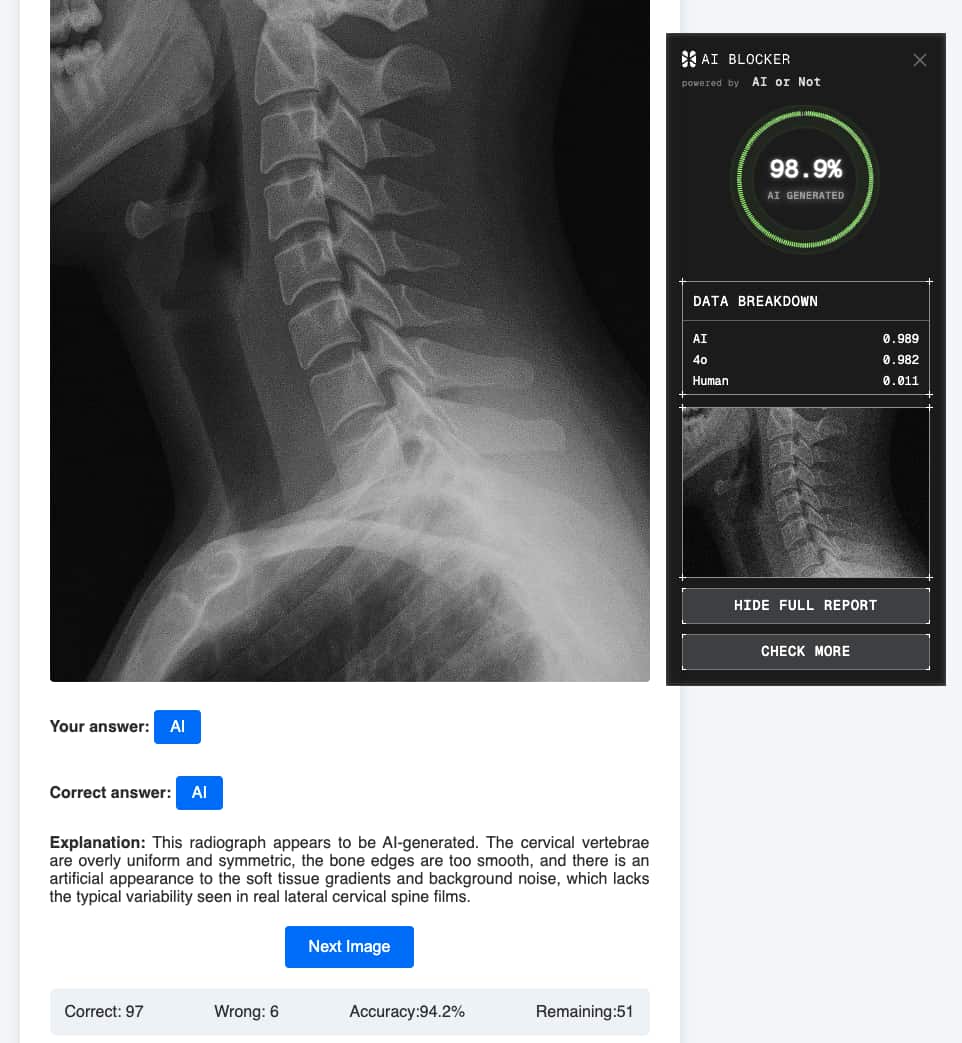
A 56% accuracy rate on a binary classification task is barely above a coin flip. In a clinical context, hospital records, insurance documentation, or courtroom evidence, that margin isn't usable.
What Purpose-Built AI Detection Does Differently
When we ran all 154 images through AI or Not, the model flagged every one of the 77 AI-generated radiographs. It also correctly identified 71 of the 77 authentic ones. Six false positives. All real chest X-rays, all scored in the 57.6-76.3% confidence band, just above the 50% threshold. We're being upfront about those.
The confidence separation across the full dataset tells the cleaner story: median confidence of 97.3% on AI-generated images, 6.4% on authentic ones. That's a 91-percentage-point gap between how the model treats fake radiographs and how it treats real ones. The errors clustered in the borderline range, not at the extremes.
Raising the confidence threshold would eliminate the false positives. It would also cost 11 missed AI detections, dropping recall to 85.7%. We kept the default threshold because in most deployment contexts, missing a fake is a worse outcome than flagging a real image for review.
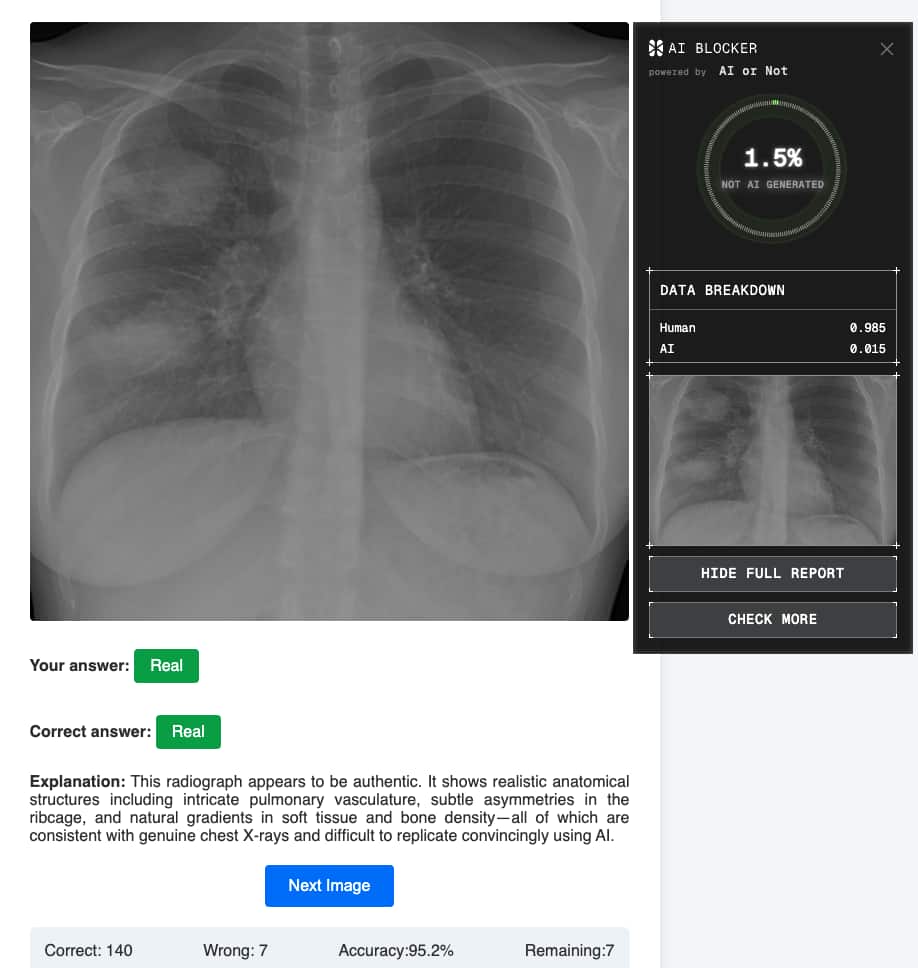
So why does the model work where LLMs don't? Because it was built for one question: was this made by an AI? AI generators leave traces, compression patterns, frequency anomalies, pixel distributions that don't match how X-ray equipment produces images. Those traces are invisible to a radiologist reading for diagnosis. They're exactly what a purpose-built detector is looking for.
We agree with the Mount Sinai researchers that no single tool solves this problem. Clinician training, image watermarking, and dataset controls all matter. But when the specific task is determining whether an image is AI-generated, a model designed for that task outperforms both radiologists and general AI systems, and the numbers show by how much.
FAQ
How accurate is AI detection for X-rays and medical images?
AI or Not scored 95% overall accuracy on a 154-image dataset of real and GPT-4o-synthesized radiographs, catching every AI-generated image in the set. The original Mount Sinai study (published in Radiology in March 2026) found that informed radiologists achieved 75% accuracy on the same type of dataset and that four general-purpose LLMs ranged from 56% to 85%. Purpose-built detection models, trained specifically to identify AI-generated content, consistently outperform both human reviewers and general AI systems on this task.
Can radiologists tell if an X-ray is AI-generated?
When told to look for synthetic images, radiologists in the Mount Sinai study achieved 75% accuracy. When not warned that AI-generated images might be present, only 7 of 17 radiologists spontaneously raised the question. The study found no correlation between years of clinical experience and detection accuracy. Radiologists are trained to read anatomy. Spotting the pixel-level artifacts that generative models leave behind is a different skill entirely.
Why can't LLMs like GPT-5 or Gemini reliably detect deepfake X-rays?
The four LLMs tested in the Mount Sinai study ranged from 56% to 85% accuracy, a spread that reflects the absence of any specialized training for this task. General-purpose LLMs bring broad image reasoning to a problem that calls for forensic specificity: identifying the digital artifacts that AI generators embed in synthetic images. A 56% accuracy rate on a binary classification task is barely above chance. In medical, legal, or insurance contexts, that's not a workable margin.
Where do AI-generated medical images come from and why does it matter?
The synthetic radiographs in the Mount Sinai dataset were produced using GPT-4o and a medical imaging model called RoentGen. Both can generate anatomically plausible X-rays that are convincing enough to pass for real ones in most clinical review contexts. The applications range from medical education and data augmentation to, at the other end, insurance fraud, fabricated evidence, and misinformation in clinical settings. The Mount Sinai team published their dataset publicly so researchers and detection tools can be tested against it.
The Mount Sinai dataset is publicly available. Anyone can download it. The same tools that produced the synthetic images in that dataset are accessible to anyone with an API key.
What do you get with AI or Not?
Instantly get your AI detection API to start building, and protecting.
AI detection covering images, text, video and audio.
All content checked gets deleted, instantly.
Start detecting AI for free, scale with pay-as-you-go.
AI to fight AI.